This is a release candidate for testing before the official v0.3.7 release. It may contain bugs. If you run into any issues, please open an issue.
Highlights
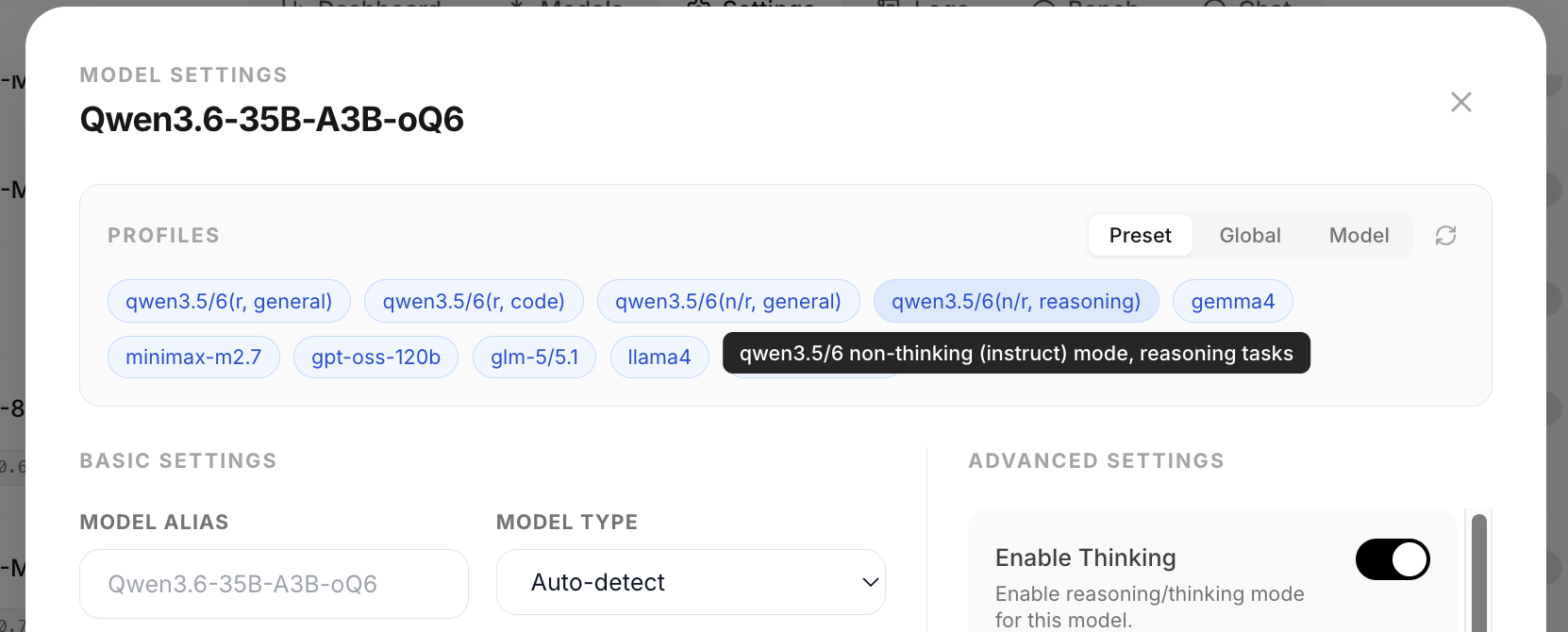
Model settings preset system
One-click vendor-recommended defaults replace the tedious 20-parameter setup dance. The model settings modal now has a unified [ Preset | Global | Model ] scope toggle, and ships with a curated omlx_preset.json bundle covering Qwen 3.5/6 (r/nr × general/code), Gemma 4, MiniMax M2.7, gpt-oss-120b, GLM-5/5.1, Llama 4, and Mistral Small 4. Values are copied from each vendor's official recommendation.
A refresh button pulls the latest bundle from omlx.ai, so when a new model lands the presets update in place without a server upgrade. Built on the per-model profile + global template data layer shipped in #853 (thanks @sxc562586657).
New Features
- Model settings profile/template data layer with atomic JSON persistence and full CRUD HTTP API (#853)
- Bundled
omlx_preset.json+POST /api/presets/refreshproxy route to fetch updates from omlx.ai - Qwen 3.6+ thinking preserved across turns on both endpoints: auto-set
preserve_thinking=Truegated on per-model template detection (#856), server-side<think>reconstruction from client-providedreasoning_content/ Anthropicthinkingblocks (#814), and nativemessage.reasoning_contentfield path for supporting templates to avoid the whitespace round-trip (#884) - Global idle timeout dropdown (None / 15m / 30m / 1h / 2h / 8h / 24h) in admin Resource Management. Per-model
ttl_secondsstill wins, pinned models exempt, live-applies without restart (#868) hot_cache_onlytoggle to run KV cache entirely in RAM with zero SSD I/O. Closes #605 (#864)- Qwen3-VL reranker and embedding auto-detection;
/v1/reranknow accepts{text, image}dicts (URL, base64, local path). Closes #877 - StatusKit Auto-Fix for Tahoe 26.x menubar visibility: one-click flips
isAllowedin the ControlCenter group container plist + restarts ControlCenter, with atomic write + backup + Full Disk Access deep-link. Bartender-aware conflict dialog also added - One-shot post-launch status-item recreate for the Tahoe registration race, About panel polish, dedicated menubar log at
~/Library/Application Support/oMLX/logs/menubar.log, andomlx diagnose menubarCLI - 4 new intelligence benchmarks (BBQ, MathQA, MMLU-Pro, SafetyBench) with per-category UI grouping (Knowledge / Commonsense & Reasoning / Math / Coding / Safety & Alignment). Thanks @michal-stengg (#837)
reasoning_contentaccepted on OpenAIMessagerequest model; Anthropicthinkingblocks preserved on the native tool-calling assistant branch (previously dropped) (#814, #884)- 1% granularity on Memory Limit and Cold Cache Limit sliders
Bug Fixes
- Fix Qwen3.6 MoE SpecPrefill silently degrading to no-op. The llama extractor assumed Qwen3-Next's gate-split
q_projand dropped per-headq_norm. Dedicated_qwen36_extract_queriespath restores the speedup (11.87 → 25.9 tok/s on Qwen3.6-35B-A3B-4bit-DWQ). Gemma 3 text / Qwen3 vanilla / EXAONE4 / DOTS1 / Klear / Apertus also benefit. Idea and measurements by @mrtkrcm (#846) - Fix whitespace round-trip in
<think>reconstruction on Qwen 3.6+ templates by using the nativemessage.reasoning_contentfield, improving prefix cache reuse on multi-turn reasoning (#884) - Fix hot_cache_only crashing or disabling caching entirely: the
paged_ssd_cache_dir=Nonepath hit an early-return guard that turned off all caching, and storing livemx.arrayinference objects in hot cache entries caused Metal GPU kernel panics on large caches (#864) - Fix cached VLM prefill crashing with
AttributeErroron non-mRoPE models (Gemma 4, Pixtral, LLaVA) when the vision-feature cache served a hit (#881) - Fix Gemma 4 SpecPrefill compatibility. Cherry-picks @apetersson's initial fix and completes the Gemma 4-specific handling. Closes #668 (#851)
- Fix
preserve_thinking=Trueauto-set applying to templates that don't support the kwarg, plus 23 missingdetect_preserve_thinkingunit tests from #814 (#856) - Fix 500 on chat template render when a client echoed back
tool_calls.argumentsas a non-JSON-object value (python repr, truncated JSON, empty string). Validated at ingress now, 422 instead of 500. Closes #854 - Fix tool call silently dropped when mlx-lm's
qwen3_coderparser raisedSyntaxErroronast.literal_evalfor non-python-literal argument values. Falls back to regex parser with a warning. Closes #882 - Fix MiniMax parallel tool calls dropped when a single
<minimax:tool_call>block contained multiple<invoke>s (mlx-lm bumped to a401730) - Fix per-model Serving Stats filter zeroing every counter for model IDs addressed by alias (
model_alias, Anthropic names via/v1/messages, integration aliases from #634). Closes #875 - Fix spurious "Custom" profile badge caused by
ttl_secondsbeing compared as a universal profile field. TTL is now an excluded operational setting (#868) - Fix composer height not resetting after submit and user markdown overflowing the chat pane. Thanks @chulanpro5 (#887)
- Fix menubar visibility false-positives from fullscreen video / slideshows by dropping the mid-session probe; relies on launch-time probe + one-shot recreate only
New Contributors
- @mrtkrcm: Qwen3.6 MoE SpecPrefill (#846)
- @michal-stengg: intelligence benchmarks (#837)
- @RepublicOfKorokke, @fqx: hot_cache_only (#701 / #864)
- @apetersson: Gemma 4 SpecPrefill initial fix (#851)
- @chulanpro5: chat composer fix (#887)