Highlights
oQ — oMLX universal dynamic quantization
Quantization should not be exclusive to any particular inference server. oQ produces standard mlx-lm compatible models that work everywhere — oMLX, mlx-lm, and any app that supports MLX safetensors. No custom loader required.
oQ is a data-driven mixed-precision quantization system for Apple Silicon. Instead of assigning bits by fixed rules or tensor type, oQ measures each layer's actual quantization sensitivity through calibration and allocates bits where the data says they matter most. See the oQ documentation for details.
Benchmarks (Qwen3.5-35B-A3B)
| Benchmark | Samples | 2-bit mlx-lm | 2-bit oQ | 3-bit mlx-lm | 3-bit oQ | 4-bit mlx-lm | 4-bit oQ |
|---|---|---|---|---|---|---|---|
| MMLU | 300 | 14.0% | 64.0% | 76.3% | 85.0% | 79.7% | 83.3% |
| TRUTHFULQA | 300 | 17.0% | 80.0% | 81.7% | 86.7% | 87.7% | 88.0% |
| HUMANEVAL | 164 (full) | 0.0% | 78.0% | 84.8% | 86.6% | 87.2% | 85.4% |
| MBPP | 300 | 0.3% | 63.3% | 69.0% | 72.0% | 71.7% | 74.3% |
- oQ2-oQ8 levels with sensitivity-driven mixed-precision bit allocation
- oQ3.5 base 3-bit + routed expert down_proj 4-bit (Super Weights protection)
- AWQ weight equalization rewritten from scratch following the llm-compressor reference implementation. fixed critical double-scaling bug on hybrid attention models (Qwen3.5) and added per-layer mask-aware calibration
- Sensitivity-driven budget plan. mandatory lm_head 8-bit protection, then data-driven tier allocation (+4/+2/+1 bits) with greedy fallback. no hardcoded tensor-type priorities — calibration data decides which layers matter
- Proxy sensitivity model. select a quantized version of the source model for layer sensitivity analysis with ~4x less memory. 90% top-10 overlap with full-precision measurement validated on Qwen3.5-35B
- New calibration dataset. 600 samples from codeparrot/self-instruct-starcoder (real code), allenai/c4 (web text), Open-Orca (conversation), gsm8k (reasoning), and wikipedia multilingual. replaces the old HumanEval/MBPP-only code samples
- VLM support. quantize vision-language models with vision weight preservation (fp16)
- FP8 model support. use native FP8 models (MiniMax, DeepSeek) as quantization source
- MiniMax M2.5 support. block_sparse_moe architecture with SwitchGLU fused experts
- DeepSeek V3.2 support. shared_experts (plural) + MLA projections. MLP AWQ works, MLA attention AWQ planned
- Nemotron support. backbone.embeddings path detection for sensitivity measurement on hybrid Mamba+MoE+Attention architecture
- AWQ grid size setting. configurable n_grid (10 fast / 20 recommended) from the web UI
- HuggingFace Hub uploader. upload quantized models directly from the dashboard
- blocks inference requests during quantization to prevent conflicts
Intelligence benchmark suite
Evaluate model intelligence across knowledge, reasoning, math, and coding benchmarks. All datasets bundled locally for offline use.
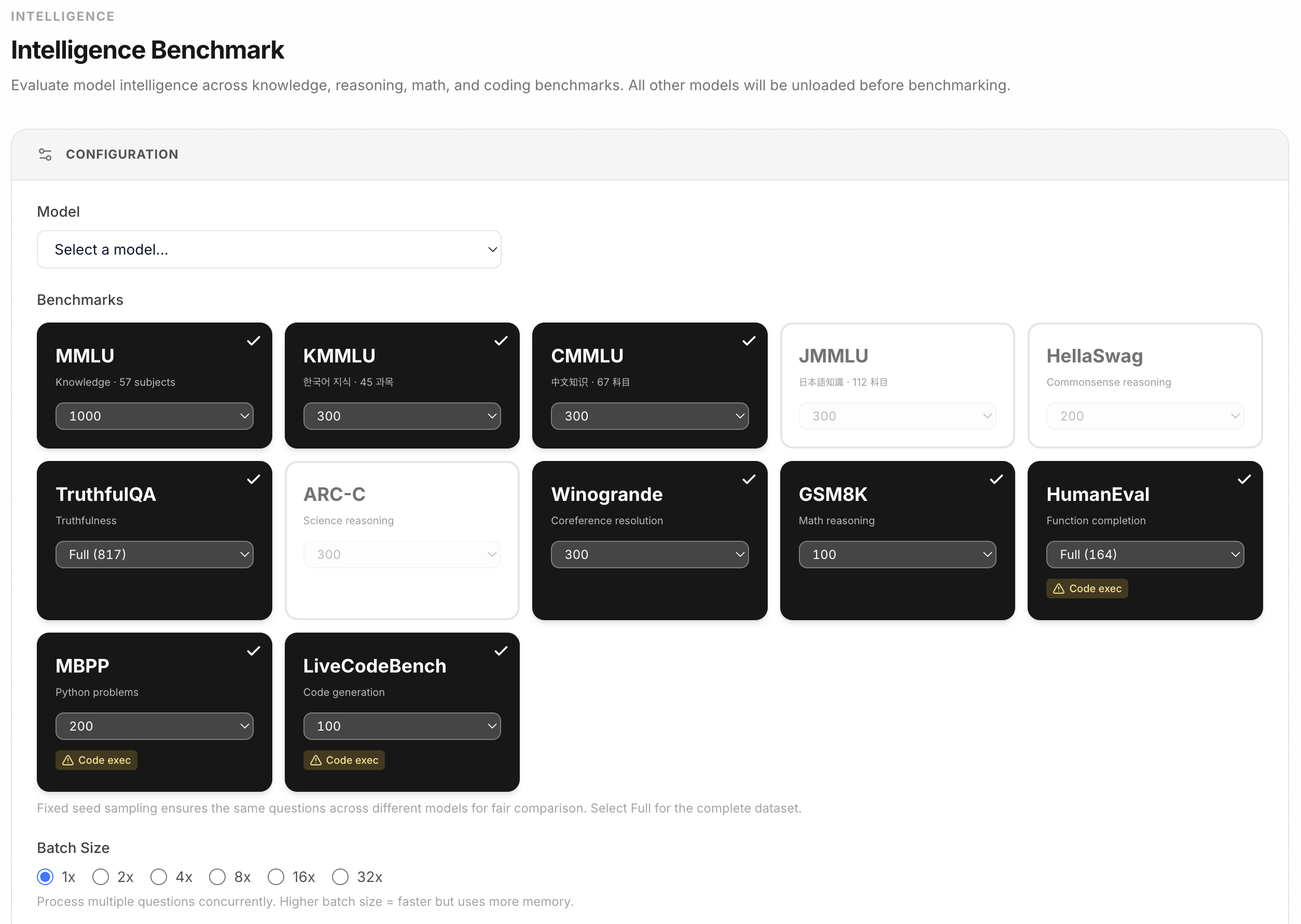
- Knowledge: MMLU, ARC-Challenge, KMMLU (Korean), CMMLU (Chinese), JMMLU (Japanese)
- Reasoning: HellaSwag, Winogrande, TruthfulQA, GSM8K
- Coding: HumanEval (164 function completions, pass@1), MBPP
- benchmark queue for sequential multi-model evaluation with persistent results
- comparison table with mode/sample columns and text export
- sample size options: 30/50/100/200/300/500/1000/2000/Full
- batch processing: 1x/2x/4x/8x/16x/32x
- download raw results as JSON
New Features
- Prefill memory guard. prevents kernel panics on large context by detecting head_dim>128 O(n^2) SDPA fallback and enforcing safe prefill chunk sizes
- Native BERT/XLMRoBERTa embedding. load BERT-family embedding models (bge-m3, mxbai-embed) without mlx-embeddings fallback (#330 by @yes999zc)
- Jina v3 reranker. reranking via
<|score_token|>logits for jinaai/jina-reranker-v3-mlx (#331 by @yes999zc) - Partial mode. assistant message prefill support for Moonshot/Kimi K2 models (
partialfield +namefield passthrough) (#306 by @blightbow) - Codex smart config merging. non-destructive config merge with reasoning model auto-detection (#249 by @JasonYeYuhe)
- i18n normalization. normalize translation files against en.json with missing key detection (#247 by @xiaoran007)
- Web dashboard generating status. show generating status for active requests after prefill completes
Experimental Features
- SpecPrefill. attention-based sparse prefill for MoE models. reduces prefill compute by skipping low-attention tokens. system prompt is protected from token dropping to preserve instruction following.
Bug Fixes
- Fix lucide icon rendering race condition with Alpine.js microtask
- Fix chat streaming failure not sending error message to client (#342)
- Fix TTL auto-unload during benchmark causing Metal GPU crash
- Fix MC benchmarks (MMLU, HellaSwag, TruthfulQA) always scoring 0% due to max_tokens=1
- Fix HumanEval scoring. prepend prompt imports when model returns function only
- Fix MBPP scoring. include test cases in prompt so model uses correct function name
- Fix benchmark code extraction. extract last answer/code block instead of first
- Fix benchmark penalties. force neutral presence_penalty=0 and repetition_penalty=1
- Fix think prefix false positive for disabled thinking patterns (
<think></think>) - Fix responses API image support for VLM + missing prompt_tokens in completions usage
- Fix SSE streaming behind nginx reverse proxy (X-Accel-Buffering header) (#309)
- Fix CausalLM-based embedding model detection (Qwen3-Embedding) (#327)
- Fix web dashboard unload tooltip clipping in active models box (#314)
- Fix web dashboard 401 warning log spam from dashboard polling
- Fix web dashboard model settings not showing for embedding/reranker models
- Fix PEP 735 dependency-groups for
uv sync --dev(#305 by @blightbow)
New Contributors
- @blightbow made their first contribution in #305
- @yes999zc made their first contribution in #330
- @JasonYeYuhe made their first contribution in #249
- @xiaoran007 made their first contribution in #247
Full changelog: v0.2.19...v0.2.20