Download the DMG that matches your macOS version (sequoia or tahoe).
If you're on an M5 Mac, you must use themacos26-tahoeDMG for M5 Neural Accelerator.
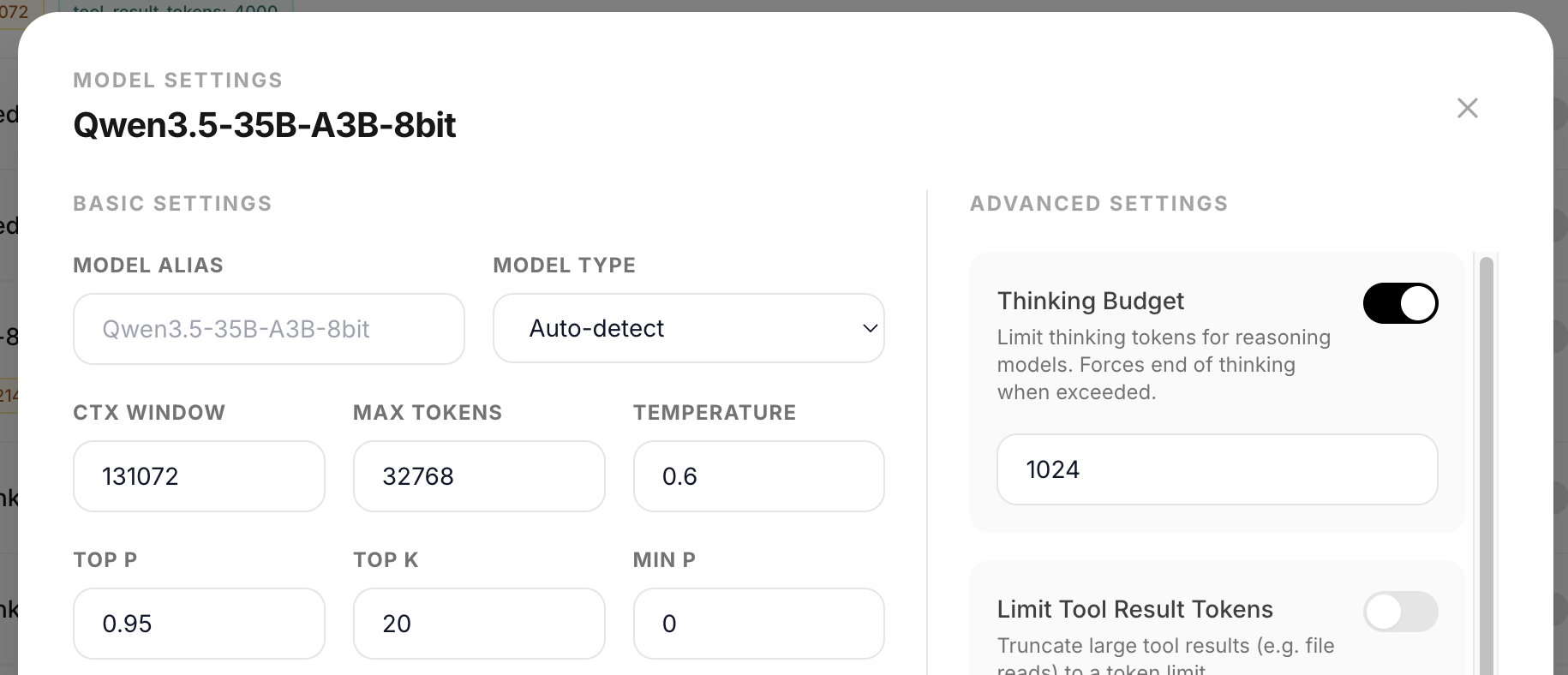
Highlights: thinking budget support
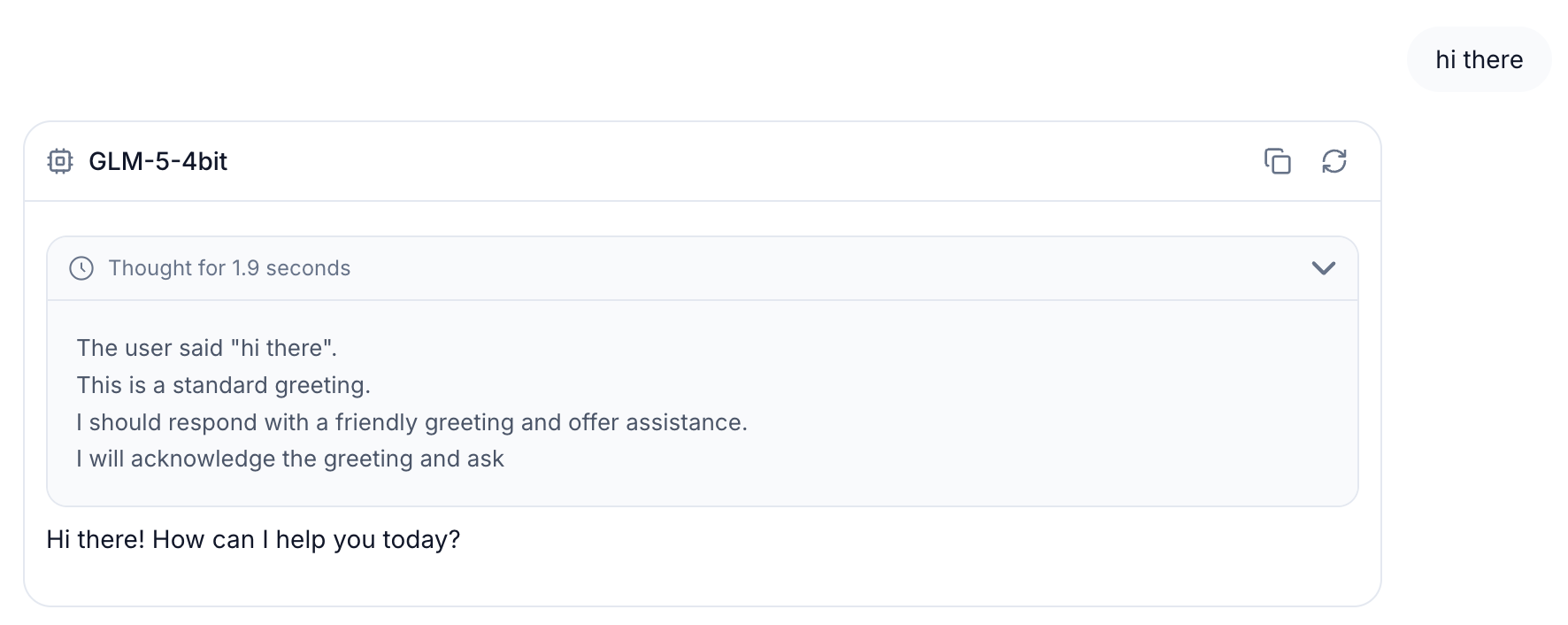
- Thinking budget for reasoning models. you can now limit how many tokens a model spends on reasoning. set it per-model in the admin panel or per-request via the API. when the budget is exceeded, thinking is force-closed and the model transitions to the actual response.
New Features
Thinking budget (#285)
- per-model thinking budget toggle + token count in admin panel (advanced settings)
- per-request
thinking_budgetparameter for OpenAI API,thinking.budget_tokensfor Anthropic API - uses logits processor to force close-think sequence when budget exceeded (same approach as vLLM/SGLang)
- auto-detects the correct
</think>transition pattern from each model's chat template (handles Qwen3, DeepSeek, GLM, MiniMax, Step etc.) - suppresses duplicate
</think>tokens after forced close - zero overhead when budget is not set. near-zero overhead when active
- works for both LLM and VLM. no impact on embedding, reranker, or any cache system
Bug Fixes
- fix disable
mx.compileon runtime failure to prevent repeated warnings on every subsequent call
Notes
- tip for Qwen3.5-35B-A3B users: if reasoning (
enable_thinking) is true, the model may emit EOS during tool calling and stop generation mid-turn. if you're using Qwen3.5 for agentic coding, go to model settings → Chat Template Kwargs, setenable_thinkingtofalseand check force.
full changelog: v0.2.17...v0.2.18